

In der Entwicklungsphase von KI Anwendungen sind lokale Modelle ein zentraler Bestandteil des Alltags. Gerade bei der Arbeit mit mehreren lokalen Entwicklungs- und Testsystemen stellt sich häufig die Herausforderung, wie man diese effizient verteilt und verwaltet. Traditionell lädt jeder Computer die benötigten Modelle lokal aus dem Internet herunter, was zu wiederholten Downloads, hohem Bandbreitenverbrauch und erhöhtem Verwaltungsaufwand führt.
Lösungsansatz
Um diese Probleme zu lösen, ist es nahe liegend, alle Modelle auf einem zentralen NFS-Server vorzuhalten. Jedoch bringt die Netzwerk-basierte Speicherung mit sich, dass das Laden der Modelle langsamer ist. In diesem Artikel zeigen wir, wie man dieses Problem mit cachefilesd lösen kann – einem Dienst, der NFS-Dateien lokal zwischenspeichert und somit die Netzwerklatenz reduziert, ohne zusätzlichen Verwaltungsaufwand zu erfordern.
Es gibt da mehrere mögliche Auswege:
- Manuelles Kopieren der Modelle zwischen den PCs. Das ist aufwändig, fummelig und damit zeitintensiv und fehlerträchtig.
- Man kann eine eigen Modell-Registry aufsetzen. Dafür sollte sich prinzipiell jede Docker Regsitry eignen. Damit muss man die Modelle nur einmalig aus dem Internet laden, kann diese dann in die eigene Registry pushen, und von dort können alle PCs versorgt werden.
- Speichern aller Modelle auf einem zentralen Server, auf den Ollama direkt über das lokale Netzwerk zugreift. Ohne entsprechend leistungsfähige Netzwerkinfrastruktur (mindestens 10GBit) ist das allerdings recht langsam.
In diesem Artikel verfolgen wir den dritten Ansatz, allerdings mit einem schlauen Kniff: Linux untersützt bei NFS lokales Caching. Damit können wir ohne eine eigene Registry zu betreiben alle Modelle effizient verwalten und gleichzeitig die Netzwerkbelastung reduzieren. Das beste daran: Sollte der lokale Cache zu viel Platz beanspruchen, wird dieser automatisch aufgeräumt.
Zentrale Modellbereitstellung mit NFS
In vielen KI-Projekten werden Modelle auf mehreren Rechnern repliziert, um die Ausführung von KI-Anwendungen lokal zu ermöglichen. Diese Vorgehensweise hat mehrere Nachteile:
- Wiederholte Downloads: Jeder Server lädt das gleiche Modell erneut herunter
- Hoher Bandbreitenverbrauch: Speziell bei großen Modellen (z. B. LLMs) kann dies erhebliche Netzwerkressourcen beanspruchen
- Verwaltungsaufwand: Bei Updates müssen alle Server manuell aktualisiert werden
- Speicherplatz ineffizient: Gleiche Dateien werden auf mehreren Servern gespeichert
Die Lösung besteht darin, alle Modelle auf einem zentralen NFS-Server zu speichern und die KI-Server über dieses Netzwerk auf die Modelle zuzugreifen. Damit werden die Modelle einmalig an einem Ort gespeichert und stehen allen verbundenen Computern zur Verfügung. Dies bietet mehrere Vorteile:
- Zentrale Verwaltung: Modelle müssen nur einmal heruntergeladen und verwaltet werden.
- Einfacher Zugriff: Alle KI-Server haben direkten Zugriff auf die zentral gespeicherten Modelle.
Allerdings führt dieser Ansatz zu langsamen Zugriffen, da Modelle über das Netzwerk geladen werden müssen. In diesem Artikel beleuchten wir eine konkrete Lösung mittels NFS Caching.
NFS Freigabe erstellen
Um alle Modelle auf einem NFS Server abzuspeichern braucht es natürlich als erstes eine entsprechende Ordnerfreigabe auf einem NFS Server. Dafür kommen unterschiedlichste Optionen in Betracht, zum Beispiel ein NAS von Synology, QNAP etc oder auch ein Linux Server. An dieser Stelle möchte ich nicht auf die Details eingehen, da diese eben sehr stark von der Software des NAS abhängen.
Nehmen wir im folgenden an, dass das entsprechende Verzeichnis über NFS wie folgt freigegeben wurde:
- NFS-Servername: nfs-server.lan
- NFS-Verzeichnisnam: /volume1/ollama-models
- NFS-Version: 4.1
NFS Mount einrichten
Nachdem auf dem NAS eine entsprechende Freigabe für NFS eingerichtet worden ist, muss diese Freigabe nun auf den NFS Clients (also den KI Servern) eingerichtet werden. Hierfür müssen wir auf jedem NFS Client zunächst ein lokales Verzeichnis anlegen, das Verbindungspunkt zum NFS Server dient („mount point“):
sudo mkdir /mnt/ollama-modelsDann können wir das Verzeichnis an diesem Verbdinspunkt einhängen:
sudo mount -t nfs nfs-server.lan:/volume1/ollama-models /mnt/ollama-modelsMount dauerhaft konfigurieren
Um nicht nach jedem Neustart des Rechners das vom NFS Server freigegebene Verzeichnis neu einhängen zu müssen, können wir einfach einen Eintrag in der Datei „/etc/fstab“ hinzufügen:
nfs-server.lan:/volume1/ollama-models /mnt/ollama-models nfs4 auto,async,rsize=131072,wsize=131072,noatime,nodiratime,acDie zusätzlichen Optionen helfen auch noch ein wenig bei per Performance:
- auto – Das Verzeichnis wird automatisch eingehängt
- async – bewirkt dass alle Schreibzugriffe im Hintergrund ausgeführt werden
- rsize=131072 – legt die maximale Größe für einen einzelnen Lesevorgang auf 128KB fest
- wsize=131072 – legt die maximale Größe für einen einzelnen Schreibvorgang auf 128KB fest
- noatime – Unterdrückt die Speicherung der letzten (reinen Lese-)Zugriffszeit auf einzelne Dateien
- nodiratime – Unterdrückt die Speicherung der letzten (reinen Lese-)Zugriffszeit auf einzelne Verzeichnisse
- ac – Schaltet Attribute Caching ein
Sobald der Eintrag in der /etc/fstab erfolgt ist, kann das Verzeichnis dann etwas einfach manuell eingehängt werden:
sudo mount /mnt/ollama-modelsOllama einrichten
Jetzt haben wir also ein Verzeichnis, das physikalisch auf einem NFS Server liegt und lokal unter „/mnt/ollama-models“ eingehängt ist. Nun müssen wir Ollama allerdings noch mitteilen, dass es dieses Verzeichnis verwenden soll, um auf die Sprachmodelle zuzugreifen.
Ollama konfigurieren
Standardmäßig erwartet Ollama in einem Verzeichnis „.ollama“ im Home-Verzeichnis des ausführenden Users alle Modelle. D.h. wenn ich als „kaya“ an meinem Linux System angemeldet bin, und mein Heimatverzeichnis unter „/home/kaya“ liegt, dann wird Ollama im Verzeichnis „/home/kaya/.ollama“ alle Modelle bei „ollama pull <model_name>“ ablegen und bei „ollama serve <model_name>“ laden.
Nun möchten wir aber nun Ollama dazu bewegen, stattdessen das NFS Verzeichnis zu verwenden. Derartige Optionen können bei Ollama relativ einfach über Umgebungsvariablen verändert werden, in diesem Fall über die Umgebungsvariable „OLLAMA_MODELS“:
# Set model directory for all following Ollama commands
export OLLAMA_MODELS=/mnt/ollama-models
# Pull model
ollama pull phi4
# Serve model
ollama serve phi4Ollama mit systemd
Falls Ollama als Systemdienst mit systemd betrieben wird, dann muss die Umgebungsvariable entsprechend im Service hinterlegt werden. Den Service kann man am einfachsten mit dem folgenden Befehl editieren:
sudo systemctl edit ollama.serviceIn dem darauf sich öffnenden Editor muss man dann nur noch die Umgebungsvariable korrekt eintragen:
[Service]
Environment="OLLAMA_MODELS=/mnt/ollama-models"Ollama mit Docker
Docker ist immer wieder eine schöne Lösung, um Software auf einem PC zu installieren. Das gilt natürlich auch für Ollama, und mit docker compose können wir recht elegant ein NFS Verzeichnis angeben, ohne dieses vorher explizit lokal gemounted zu haben. Die folgende docker-compose.yml Datei zeigt dies konkret:
services:
ollama:
image: ollama/ollama:
read_only: true
ports:
- "11434:11434"
volumes:
- models:/root/.ollama
- type: tmpfs
target: /tmp
volumes:
models:
driver_opts:
type: nfs
o: addr=nfs-server,nolock,hard,rw,async,rsize=131072,wsize=131072
device: ":/volume1/ollama-models"NFS Caching mit cachefilesd
Obwohl das zentrale Speichern von Modellen viele Vorteile bietet, gibt es auch einen Nachteil: Das Laden der Modelle über das Netzwerk ist oft langsam im vergleich zu einer lokalen SSD oder NVMe. Dies kann die zu unangenehmen Wartezeiten führen, sobald Modelle neu eingeladen werden müssen.
Um die Netzwerkbelastung zu reduzieren, können wir den Dienst cachefilesd verwenden, um einen lokalen Cache auf allen KI-Servern einzurichten.
Was ist cachefilesd?
cachefilesd ist ein Daemon, der das Caching von Dateien auf dem lokalen Dateisystem ermöglicht. Es arbeitet auf der Ebene des Dateisystems und erkennt automatisch, welche Dateien am häufigsten gelesen werden, und speichert diese lokal. Dabei wird die lokale Cache-Größe automatisch verwaltet.
Funktionsweise von cachefilesd
cachefilesd implementiert eine LRU-Strategie (Least Recently Used) zur Cache-Verwaltung:
- Datei Lesezugriff: Wenn ein Client auf eine Datei im NFS-Verzeichnis lesend zugreift, wird diese auf dem lokalen System im Hintergrund in einem Cache-Verzeichnis zwischengespeichert.
- Erneuter Lesezugriff: Wenn der Client ein zweites Mal auf die selbe Datei zugreift, wird cachefilesd dies erkennen, und die Anfrage direkt aus dem lokalen Cache bedienen – allerdings erst nachdem eine kurze Rücksprache mit dem NFS Server sichergestellt wurde, dass die Datei auf dem Server nicht verändert wurde.
- Datei Schreibzugriff: Schreibende Zugriffe durch Clients werden weiterhin direkt an den NFS Server weitergegeben. Dies stellt sicher, dass die Datei konsistent bleibt, und alle Clients immer die neueste Version sehen.
- Automatische Verwaltung: Der Daemon kümmert sich automatisch um das Hinzufügen und Löschen von Dateien und setzt hierfür eine LRU Stategie ein. D.h. sobald die Gesamtgröße des lokalen Caches einen (konfigurierbaren) Schwellwert überschritten hat, wird der Daemon die am längsten nicht mehr verwendeten Dateien aus dem Cache löschen.
Es werden nur die Lesezugriff gecached, alle Schreibzugriffe werden weiterhin direkt an den NFS Server weitergegeben. Damit ergeben sich also keine neuen Konsistenzprobleme, und der Cache beinhaltet auch keine Daten, die nicht auch auf dem NFS Server liegen.
Transparente Integration von cachefilesd
Ein wesentlicher Vorteil von cachefilesd ist seine Transparenz. Anwendungen wie Ollama merken nichts davon, dass die Dateien lokal gecached werden. Die Anwendung greift auf das NFS-Verzeichnis zu, wie gewohnt, und cachefilesd sorgt automatisch für die lokale Zwischenspeicherung.
Vorteile der Transparenz
- Keine Anpassungen erforderlich: Ollama oder andere Anwendungen benötigen keine speziellen Einstellungen
- Keine Kompatibilitätsprobleme: Die Anwendung arbeitet wie gewohnt
- Einfache Integration: Cache-Setup erfolgt auf Systemebene, nicht auf Anwendungsebene
- Unveränderte APIs: Alle Dateioperationen (Lesen, Schreiben) funktionieren unverändert
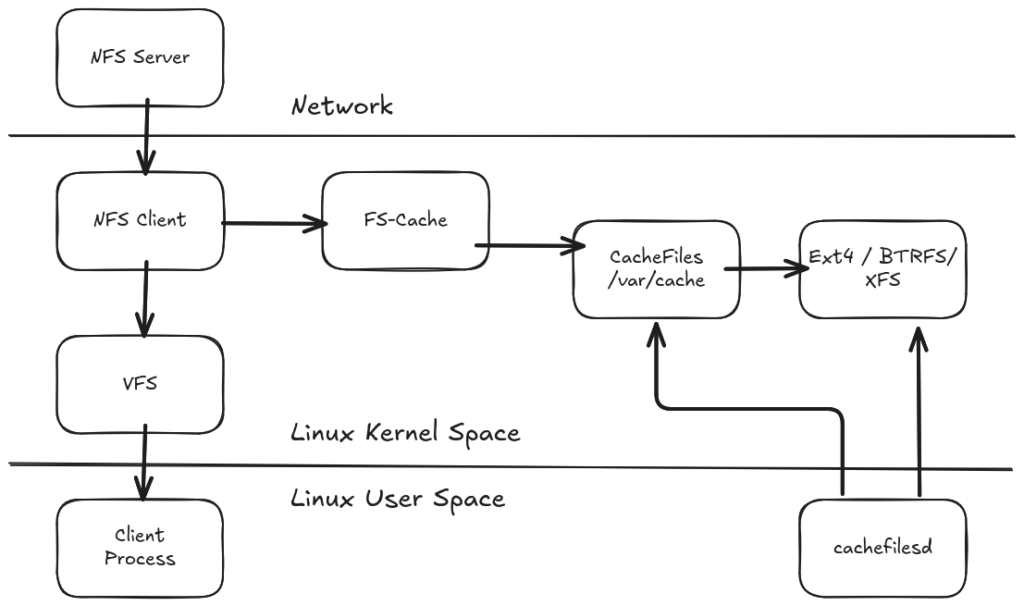
Architektur
Die grundlegende Architektur von cachefilesd ist in dem folgenden Diagramm dargestellt:
Installation von cachefilesd
Installation
Um das NFS Caching zu aktivieren, müssen wir als erstes cachefilesd installieren. Diese Anwendung steht auf vielen Linux Distributionen als fertiges Paket zur Verfügung und kann mit den entsprechenden Werkzeugen einfach installiert werden:
## Debian/Ubuntu
sudo apt update && sudo apt install cachefilesd
## CentOS/Fedora/RedHat/Rocky Linux/AlmaLinux
sudo yum install cachefilesdAktivieren und Starten von cachefilesd
Nach der Installation muss der Service noch aktiviert und gestartet werden.
Ubuntu / Debian
Auf Ubuntu und Debian Systemen muss der Dienst zuvor noch freigeschaltet werden. Hierfür muss die Datei /etc/default/cachefilesd editiert werden:
RUN=yesOhne diesen kleinen Eintrag wird der Dienst andernfalls nicht starten. Dieser Schritt ist auf Fedora nicht notwendig
Konfiguration
cachefilesd versucht, ausreichend viel freien Speicherplatz auf der Festplatte durch das Freigeben alter zwischengespeicherter Objekte aufrechtzuerhalten. Diese Eigenschaft wird als Cache-Culling bezeichnet. Diese Konfiguration kann in der /etc/cachefilesd.conf mithilfe von sechs Einstellungen durchgeführt werden:
- brun N% (Prozentsatz der Blöcke) & frun N% (Prozentsatz der Dateien): Dies beschreibt den verfügbaren Speicherplatz und die Anzahl der verfügbaren Dateien. Wenn diese Werte den eingestellten Prozentsatz überschreiten, wird das Culling deaktiviert.
- bcull N% (Prozentsatz der Blöcke) & fcull N% (Prozentsatz der Dateien): Beschreibt den verfügbaren Speicherplatz oder die Anzahl der Dateien, und wenn diese Werte unter das festgelegte Limit fallen, wird das Culling gestartet.
- bstop N% (Prozentsatz der Blöcke) & fstop N% (Prozentsatz der Dateien): Wenn hier der verfügbare Speicherplatz oder die Anzahl der verfügbaren Dateien im Cache unter ein oder beide dieser Limits fällt, wird die Zuweisung von Speicherplatz gestoppt, bis die Limits über dem eingestellten Prozentsatz liegen.
Die Einstellungen werden in der Datei /etc/cachefilesd.conf vorgenommen:
dir /var/cache/fscache
tag mycache
brun 10%
bcull 7%
bstop 3%
frun 10%
fcull 7%
fstop 3%
# Assuming you're using SELinux with the default security policy included in
# this package
# Comment this in for Fedora, leave it for Ubuntu
#secctx system_u:system_r:cachefiles_kernel_t:s0Aktivierung und Start
Danach können wir dann endlich den cachefilesd Dienst mit systemd aktivieren und starten:
sudo systemctl enable cachefilesd
sudo systemctl start cachefilesdVerwendung des Caches
Der Dienst sollte nun im Hintergrund laufen, aber er wird die Zugriffe auf NFS noch nicht beschleunigen. Denn man muss jedem NFS-Mount explizit mitteilen, dass der Zugriff darauf mit cachefilesd gecached werden soll. Dies erfolgt einfach über die Option „fsc“, die bei dem Mount mit angegeben werden muss.
sudo mount -t nfs -o fsc nfs-server.lan:/volume1/ollama-models /mnt/ollama-modelsUnd bei einem Eintrag in der Datei /etc/fstab muss ebenfalls die Option „fsc“ hinzugefügt werden:
nfs-server.lan:/volume1/ollama-models /mnt/ollama-models nfs4 auto,async,rsize=131072,wsize=131072,noatime,nodiratime,ac,fscVerwendung von Ollama in Docker mit NFS
Natürlich können wir den NFS Cache mit cachefilesd auch mit Docker verwenden. Hierfür müssen wir nach der Installation von cachefilesd lediglich die NFS Option „fsc“ hinzufügen:
services:
ollama:
image: ollama/ollama:
read_only: true
ports:
- "11434:11434"
volumes:
- models:/root/.ollama
- type: tmpfs
target: /tmp
volumes:
models:
driver_opts:
type: nfs
o: addr=nfs-server,nolock,hard,rw,async,rsize=131072,wsize=131072,fsc
device: ":/volum1/ollama-models"Cache Statistiken
Sobald der NFS Cache aktiv ist, können wir uns auch Statistiken über das Pseudofilesystem /proc anschauen:
$ cat /proc/fs/fscache/stats
Reads : DR=0 RA=297296 RF=0 RS=0 WB=0 WBZ=0
Writes : BW=0 WT=0 DW=0 WP=0 2C=0
ZeroOps: ZR=0 sh=0 sk=0
DownOps: DL=0 ds=0 df=0 di=0
CaRdOps: RD=297278 rs=297276 rf=0
UpldOps: UL=0 us=0 uf=0
CaWrOps: WR=0 ws=0 wf=0
Retries: rq=0 rs=0 wq=0 ws=0
Objs : rr=985 sr=26 foq=26 wsc=0
WbLock : skip=0 wait=0
-- FS-Cache statistics --
Cookies: n=150 v=1 vcol=0 voom=0
Acquire: n=150 ok=150 oom=0
LRU : n=0 exp=161 rmv=1 drp=0 at=0
Invals : n=0
Updates: n=731 rsz=0 rsn=0
Relinqs: n=0 rtr=0 drop=0
NoSpace: nwr=0 ncr=0 cull=1
IO : rd=297278 wr=0 mis=0Fazit
Das Kombinieren von NFS mit cachefilesd bietet eine effiziente Lösung zur Verteilung von KI-Modellen in verteilten Infrastrukturen. Durch die zentrale Speicherung und lokale Caching-Strategie werden:
- Wiederholte Downloads vermieden
- Bandbreitennutzung reduziert
- Netzwerklatenz minimiert
- Verwaltungsaufwand reduziert
Die Integration mit Tools wie Ollama und Docker Compose ermöglicht eine einfache Umsetzung in bestehende KI-Infrastrukturen. Mit minimalen Konfigurationsschritten lässt sich die Performance erheblich steigern, ohne komplexe Cache-Management-Systeme implementieren zu müssen.
Die transparente Integration von cachefilesd bedeutet, dass Anwendungen wie Ollama keine Anpassungen benötigen – sie arbeiten wie gewohnt, aber profitieren automatisch von der lokalen Caching-Strategie. Die automatische Bereinigung ungenutzter Dateien sorgt dafür, dass der lokale Speicher nicht überlastet wird, während häufig verwendete Modelle optimal zwischengespeichert werden.


